

Nvidia: Still Worth the Price?
The business is exceptional. The question is how much of the AI build-out is already priced in.

Nvidia is building the roads underneath artificial intelligence.
It does not own the apps, chatbots or enterprise workflows built on top of AI. But it supplies a large part of the infrastructure that allows AI traffic to move: GPUs, networking, software, full systems and the developer ecosystem around them.
That is what makes Nvidia so interesting. If AI usage keeps growing, someone needs to keep expanding the infrastructure underneath it. Training models, running inference, deploying agents and eventually scaling physical AI all require compute. Nvidia sits close to that layer.
But infrastructure companies can be strategically essential without automatically being great investments. The real question is not whether Nvidia matters. It clearly does. The question is whether Nvidia can keep collecting premium economics on the AI road, or whether the market is already pricing in too much of that future.
Disclaimer
Do you appreciate our publication? Then you help us enormously with a like, comment, share and/or restack.

Chapter 1: From Gaming GPUs to AI Infrastructure
The graphics origin
Nvidia did not start as an artificial intelligence company. When Jensen Huang, Chris Malachowsky and Curtis Priem founded the business in 1993, the opportunity was much narrower: graphics. Personal computers were becoming more powerful, video games were becoming more demanding, and visual computing was moving from a technical niche into a large consumer market.
The original problem was simple to understand but difficult to solve. Rendering images, textures, shadows and movement requires many small calculations to happen at the same time. A traditional CPU was not built for that kind of parallel workload. Nvidia focused on the GPU, a processor designed to do many calculations simultaneously. At first, that made the company valuable to gamers. Over time, the same architecture would become useful for scientific computing, simulations, data processing and eventually neural networks.
Gaming became Nvidia’s first major engine. The GeForce cycle gave the company a large commercial market, recurring upgrade demand and the cash flow to keep improving its architecture. Every new generation of games required better performance, more memory bandwidth, stronger drivers and better developer support. In hindsight, gaming was not just a consumer business. It helped Nvidia build the technical culture and performance discipline that later became useful in datacenters.
CUDA changed the direction
The real strategic shift came in 2006 with CUDA. CUDA allowed developers to use Nvidia GPUs for general-purpose computing, not only graphics. That changed the GPU from a graphics accelerator into a programmable compute engine. At the time, this was not an obvious mass-market opportunity. GPU computing was mainly useful for researchers, engineers and high-performance computing users, while most of the commercial world still thought about computing through CPUs.
That is what makes CUDA so important. Nvidia had to invest ahead of the market in software tools, libraries, documentation, developer education and ecosystem support, long before the commercial payoff was visible. CUDA did not immediately transform the income statement, but it changed the direction of the company. Nvidia was no longer only selling faster graphics chips into gaming. It was making the GPU useful for a much broader range of workloads.
This also made Nvidia more than a normal chip designer. Without software, a powerful GPU is difficult to use efficiently. CUDA gave developers a way to build directly on Nvidia hardware, optimize workloads and reuse code across generations. Over time, researchers learned CUDA, universities taught it, libraries were built around it, and early high-performance computing users started treating Nvidia GPUs as a serious compute layer.
Deep learning created the market
The broader market started to understand the value of that platform when deep learning began to scale. In 2012, AlexNet showed how powerful GPUs could be for training neural networks. This did not create Nvidia’s strategy from scratch. It validated a path the company had already been following for years. Neural networks require enormous amounts of repeated mathematical operations, and GPUs are naturally suited to that kind of work.
From that point onward, Nvidia’s center of gravity began shifting. Gaming remained important, but datacenter acceleration became the future. Customers were no longer buying only graphics performance. They were buying the ability to train models faster, process data more efficiently and build new AI systems.
From chips to AI infrastructure
As AI workloads grew, Nvidia had to move beyond individual chips. Training large models requires clusters of accelerators, high-speed memory, fast networking, optimized software and reliable deployment. A single GPU still matters, but the performance of the full system matters more. That pushed Nvidia into datacenter platforms such as DGX, and later deeper into networking through the acquisition of Mellanox, announced in 2019 and completed in 2020.
Mellanox gave Nvidia a stronger position in high-performance networking, including InfiniBand, which became increasingly important as AI clusters scaled. The larger the cluster, the more valuable the communication layer becomes. This is how Nvidia moved from selling graphics chips to selling AI infrastructure. The unit of value changed from the GPU to the system, and increasingly from the system to the AI datacenter itself.
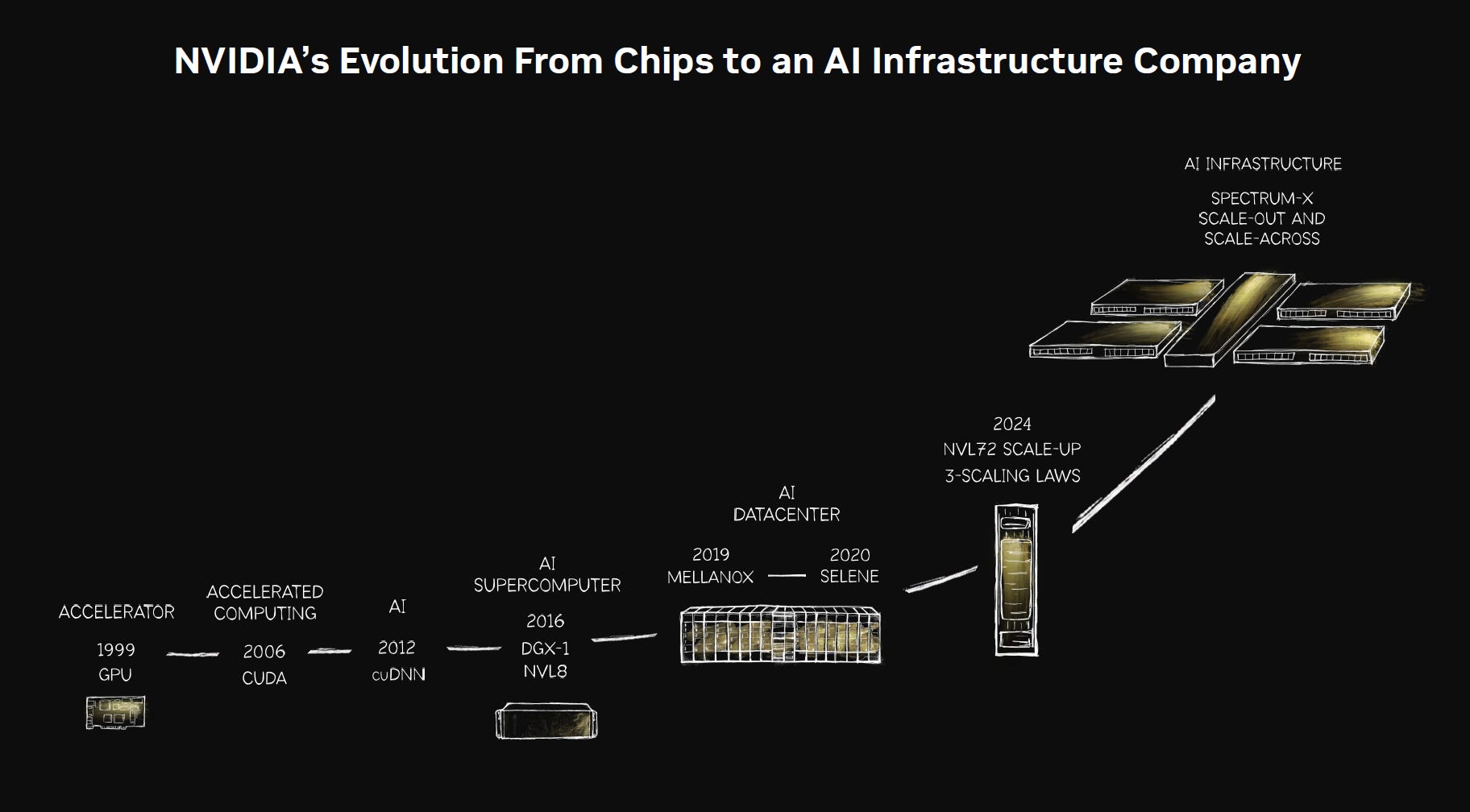
That path matters because Nvidia did not arrive at the center of AI by accident. It moved from graphics to parallel computing, from CUDA to deep learning, from datacenter acceleration to networking and full systems. By the time generative AI exploded, Nvidia already had the chips, software, developers and infrastructure stack needed to meet the demand.
The next question is what that history has become financially: how Nvidia makes money today, how much of the business now depends on AI infrastructure, and whether the current revenue and margin profile can last.
Chapter 2: The Business Model
Data Center became the company
Nvidia used to be a company with several visible pillars. Gaming was the core, Professional Visualization was relevant, Automotive offered long-term optionality, and Data Center was an attractive growth segment. That picture no longer describes the company. Nvidia is now first and foremost an AI infrastructure business.
The numbers show how dramatic the shift has become. In fiscal year 2026, Nvidia generated roughly $215.9 billion in revenue. Data Center accounted for approximately $193.7 billion of that total, or almost 90% of group sales. Gaming, once the heart of the company, generated $16.0 billion. The other segments were much smaller. The equity story has therefore changed completely: Nvidia is no longer valued primarily on consumer graphics cycles, but on whether AI infrastructure demand remains large enough to support Data Center growth, extreme margins and enormous free cash flow.
That also makes Nvidia more concentrated than it used to be. A company that once had several engines is now tied much more directly to one dominant cycle: the global build-out of AI infrastructure. This is the source of Nvidia’s strength, but also the reason the investment case has become more demanding. If Data Center remains strong, Nvidia’s financial profile can stay exceptional. If Data Center growth slows or margins normalize faster than expected, the rest of the company is no longer large enough to fully offset that pressure.
The stack is the business model
Data Center is often described as “AI chips,” but that is too narrow. Nvidia is not only selling GPUs into server racks. It is selling a broader infrastructure stack: compute, software, networking and full systems that work together to train and run AI models at scale.
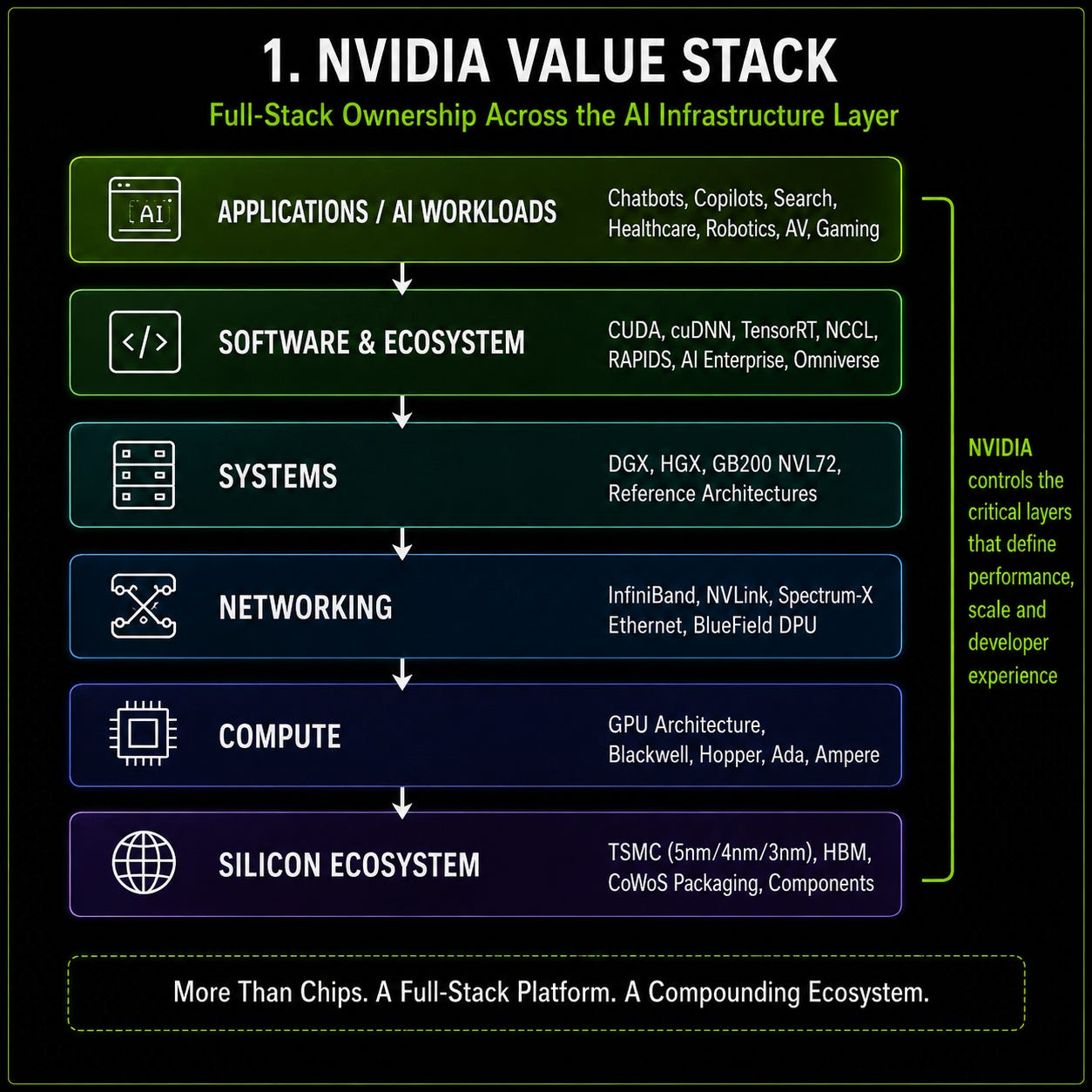
The GPU remains the most visible product, but the economics are increasingly shaped by what sits around it. CUDA gave developers a way to build directly on Nvidia hardware. Libraries such as cuDNN, TensorRT and NCCL reduce friction for AI workloads. Networking technologies such as InfiniBand, NVLink, NVSwitch and Spectrum-X become more valuable as AI clusters scale. Rack-scale systems then bring those pieces together into complete AI infrastructure.
This is why Nvidia’s business model is stronger than a normal component supplier. A customer is not simply buying a chip and comparing it against a cheaper alternative. It is buying performance, software maturity, deployment speed, system reliability and lower execution risk. In AI infrastructure, that matters. When a customer spends billions on datacenter capacity, the cheapest chip is not always the cheapest system if it creates delays, underutilization or engineering complexity.

That is also why the moat and the business model are difficult to separate. Nvidia earns exceptional economics because it does not only sell silicon. It sells a platform that combines hardware, software, networking, deployment experience and customer trust. The more customers build around that stack, the harder it becomes to treat Nvidia as a replaceable chip vendor.
Why the margins are so high
The financial result is visible in Nvidia’s margin profile. In FY2026, Nvidia reported a gross margin of 71.1% and an operating margin of 60.4%. These are not normal semiconductor margins, and they are central to the valuation debate.
Part of this profitability is structural. Nvidia is fabless, which means it designs the high-value architecture but does not carry the full capital burden of owning advanced fabs. It also benefits from software lock-in, developer familiarity, networking integration and system-level performance. For many AI workloads, Nvidia is not the cheapest option, but it is often the lowest-risk option. Customers have been willing to pay for that reliability because access to AI compute can determine competitive position.
Part of the profitability, however, is likely cyclical. Demand has been extremely strong, supply has been tight, and hyperscalers have been racing to secure capacity. That creates scarcity pricing. It is rational for Nvidia to capture that value while the market is supply-constrained, but investors should be careful about assuming that every part of today’s margin profile is permanent.
The right question is therefore not whether Nvidia deserves premium margins. It clearly does. The question is how much of the current margin profile comes from durable platform economics, and how much comes from a period in which customers need capacity faster than the supply chain can deliver it. If Nvidia remains a full-stack AI infrastructure platform with strong system-level lock-in, a 70%+ gross margin profile can be defended. If supply normalizes while AMD, custom ASICs and internal hyperscaler chips become stronger alternatives, margins may still remain high but move lower than today’s peak levels.
Gaming still matters, but no longer drives the thesis
Gaming remains strategically useful, but it no longer drives the stock. It keeps Nvidia close to a large installed base of users, developers and enthusiasts. It also gives the company a consumer platform for graphics, AI PCs and local inference. But financially, Gaming is now secondary to Data Center.
The same is true for Professional Visualization, Automotive and OEM/Other. Automotive, robotics and physical AI may become more meaningful over time, but today they are not large enough to offset a major change in Data Center demand. That does not make them irrelevant. It simply means they are optionality, not the core investment case.
This matters because the current Nvidia thesis is less diversified than the segment list suggests. Nvidia still reports several businesses, but one business now determines the company’s financial profile. The key question is not whether the next GeForce cycle is strong. The key question is whether Data Center revenue, margins and free cash flow can remain durable as the AI build-out matures.
Customer concentration and the ROI test
The strength of Nvidia’s business model comes with a clear concentration risk. A relatively small group of hyperscalers and cloud platforms drives a very large share of AI infrastructure spending. Microsoft, Amazon, Google, Meta, Oracle and other large buyers are central to the current demand cycle.
That concentration is powerful when those customers are accelerating capex. Nvidia benefits immediately when they compete for scarce capacity, upgrade to the newest systems and build ahead of demand. But the reverse is also true. If hyperscalers slow spending, digest capacity, shift more workloads to internal silicon or demand better pricing, Nvidia can feel the pressure quickly.
The reported customer concentration may not fully show the true end-customer exposure, because direct customers can include cloud providers, OEMs, ODMs, distributors or system integrators. Economically, however, the demand is still closely linked to the same small group of hyperscalers.
That brings the business model back to customer ROI. Nvidia can keep selling the roads of AI only if enough profitable traffic keeps moving over them. Cloud providers need to earn attractive returns on GPU capacity. AI labs need to monetize models. Enterprises need to turn copilots, agents and automation into productivity gains, cost savings or revenue growth. If AI becomes a broad productivity layer, Nvidia’s demand base deepens. If the revenue layer lags behind the infrastructure build-out, hyperscalers may eventually become more disciplined.
The business model in one sentence
Nvidia has built one of the highest-quality business models in the market: high growth, extreme margins, low capital intensity, massive free cash flow and a central position in the AI infrastructure cycle. But that model is now tied to demanding assumptions. Data Center must remain strong, the full-stack advantage must keep protecting margins, hyperscalers must continue spending, and end customers must prove that AI infrastructure creates enough economic value.
That is why the next chapter turns to demand. Nvidia has built the road, and for now the traffic is enormous. The question is whether that traffic is structurally durable, or whether investors are looking at the most profitable phase of an extraordinary AI capex wave.
Chapter 3: Structural Growth or Capex Wave?
The demand question
Nvidia’s business model looks exceptional today because demand has been exceptional. Hyperscalers are building AI infrastructure at a pace that would have looked unrealistic only a few years ago. AI labs need more compute to train frontier models. Cloud providers need capacity to rent to customers. Enterprises are experimenting with copilots, agents and automation. Governments are starting to treat AI infrastructure as a strategic asset.
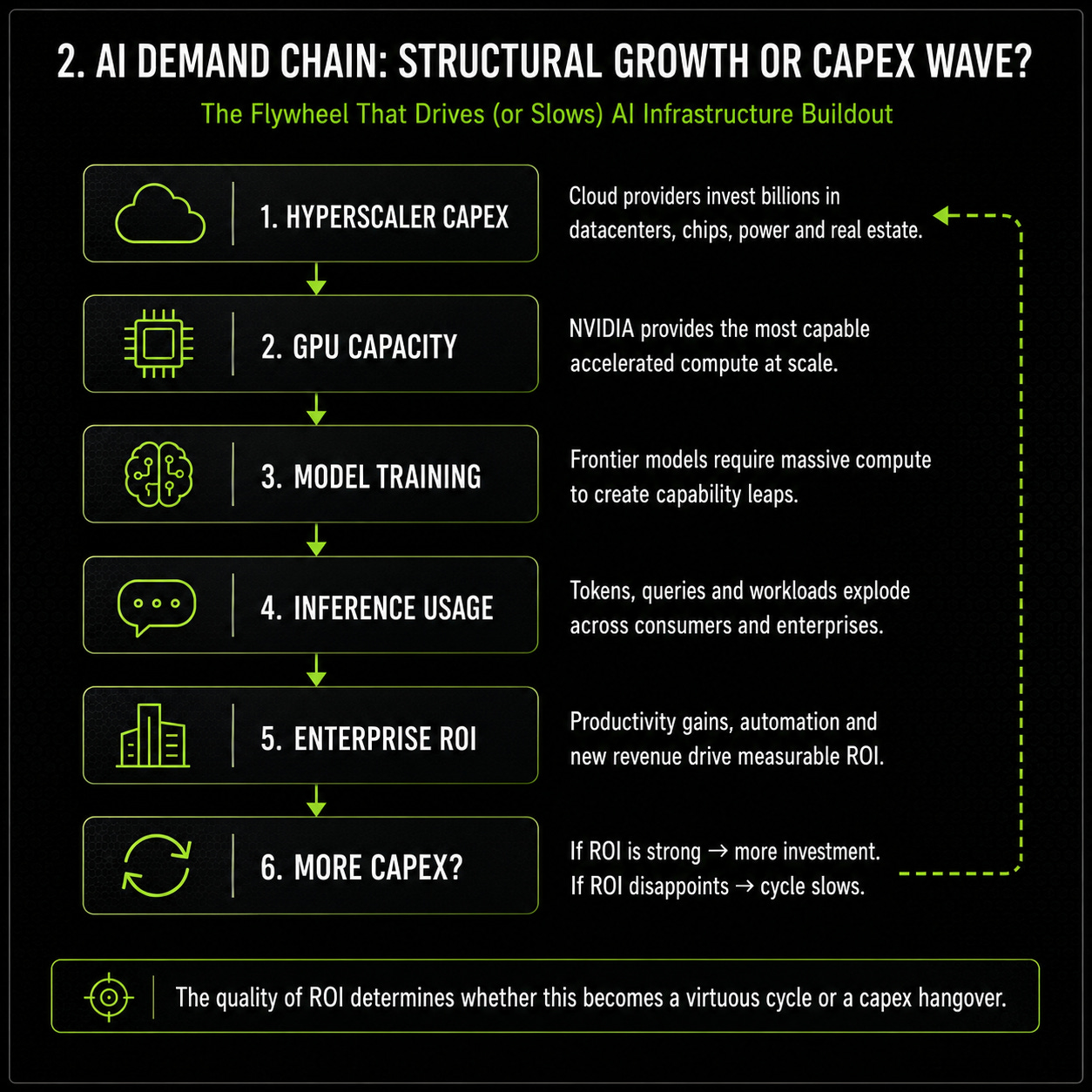
That creates a powerful demand story, but also the most important question in the thesis: how much of this demand is structural, and how much is the first extreme phase of an AI capex cycle?
That distinction matters because Nvidia is not valued like a normal growth company. The market is already pricing in years of strong AI infrastructure demand, high margins and continued leadership. “AI will grow” is therefore not enough. For Nvidia’s current economics to remain durable, the full demand chain has to keep working: hyperscalers must continue spending, cloud customers must keep renting GPU capacity, inference must scale, enterprise AI must move from pilots to production, and lower token costs must lead to more usage rather than less infrastructure demand.
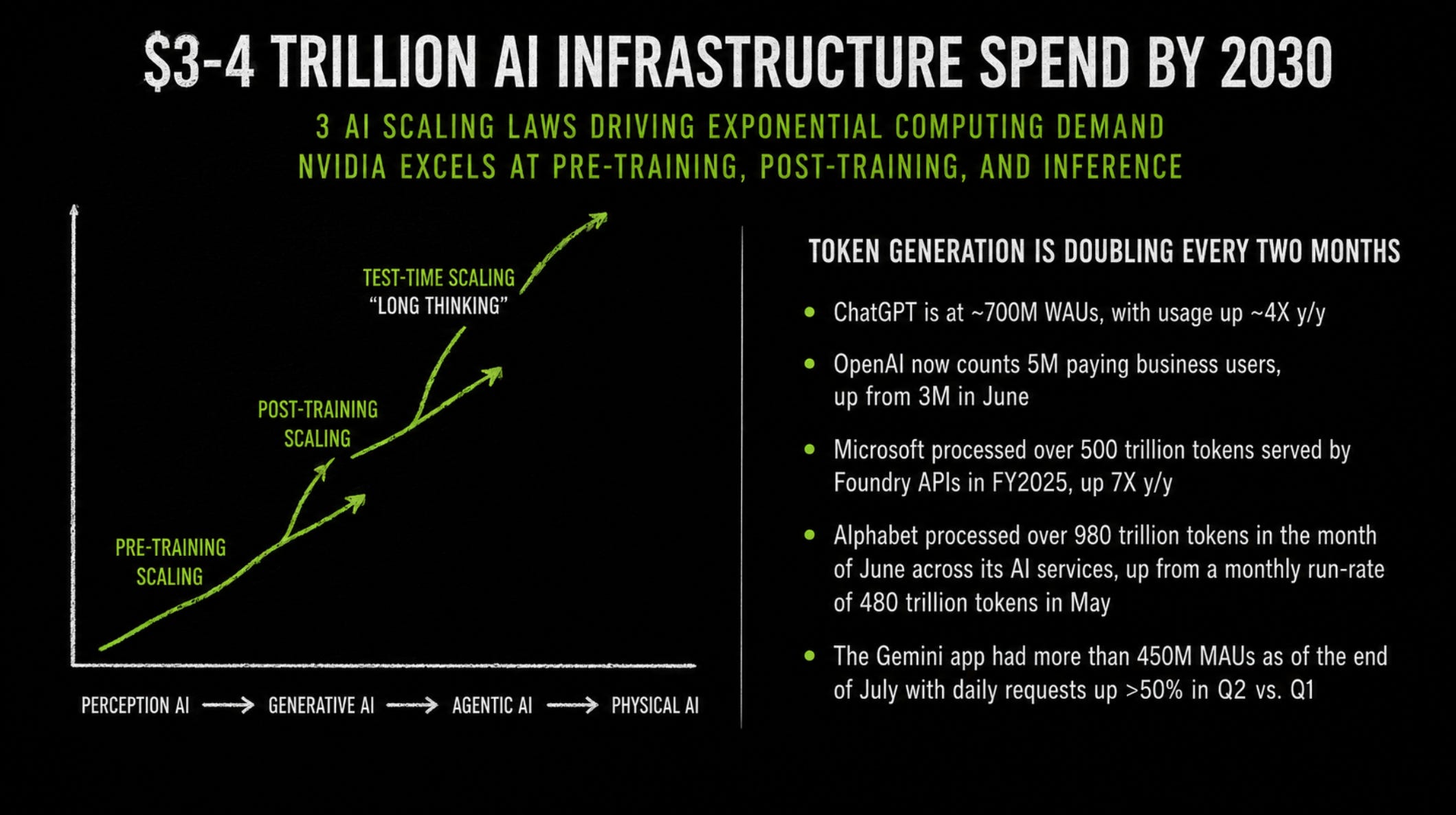
Hyperscalers are driving the current cycle
The first and most visible source of demand is hyperscaler capex. Microsoft, Amazon, Google, Meta, Oracle and other large cloud platforms are rebuilding parts of their datacenter footprint around accelerated computing. This is not small experimental spending. These companies are committing enormous amounts of capital because AI infrastructure has become strategically important. A cloud provider without enough AI compute risks losing workloads, developers, enterprise customers and model partnerships.
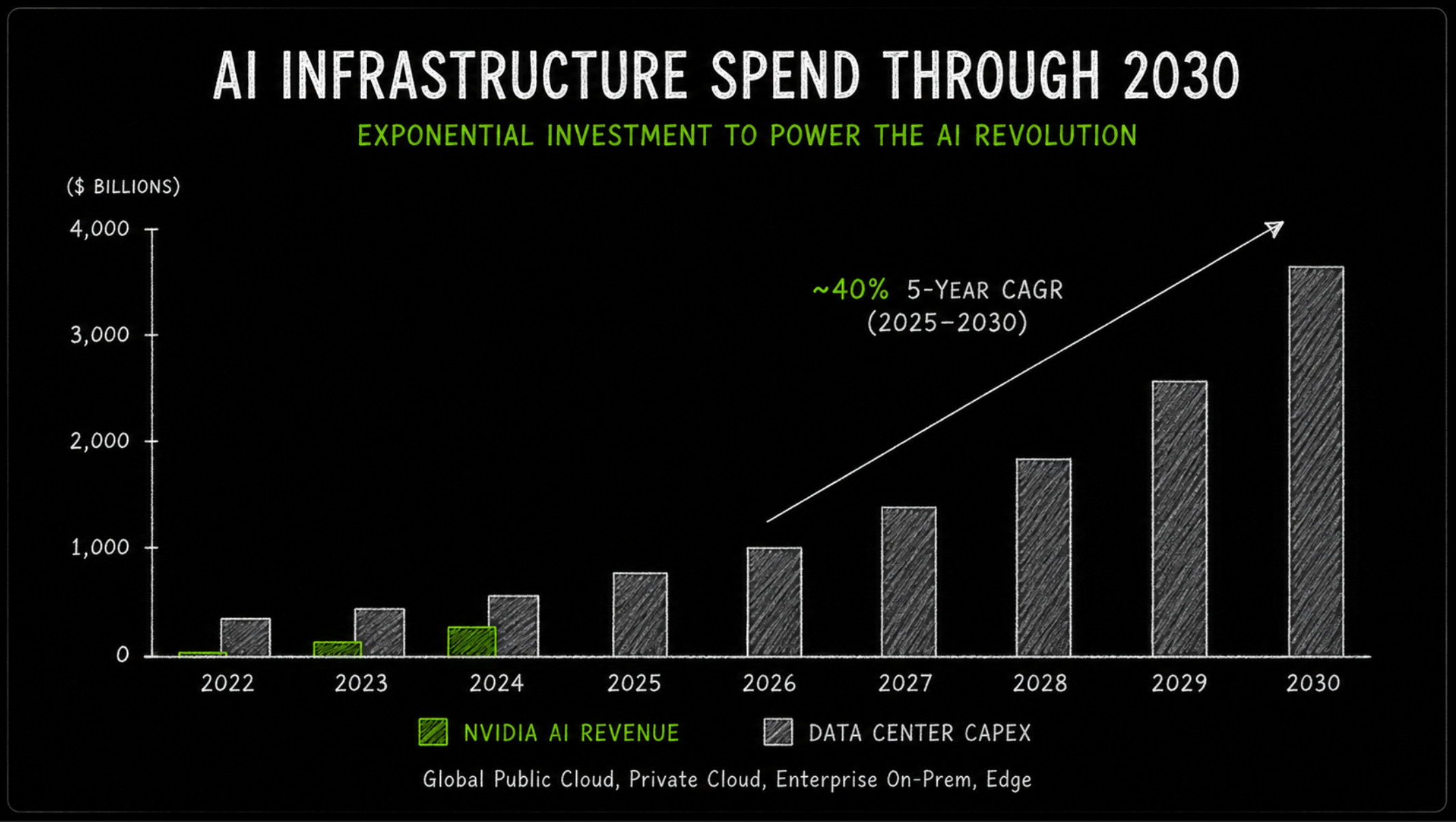
For Nvidia, this has created an almost ideal customer base. Hyperscalers have the balance sheets to spend aggressively, the cloud platforms to monetize capacity, and the strategic need to stay close to the frontier. When compute is scarce, Nvidia captures premium economics because customers are not only buying hardware; they are buying speed, certainty and time-to-market.
The weakness is concentration. Nvidia’s demand is heavily linked to the capital allocation decisions of a relatively small number of companies. That is powerful when those companies are accelerating capex, but risky if they enter a digestion phase. Hyperscalers do not need to abandon AI for Nvidia to feel pressure. A slower upgrade cycle, better utilization discipline, more internal silicon or tougher pricing negotiations would already change the quality of Nvidia’s growth.
Training started the wave, inference must extend it
The first wave of demand was driven largely by training. Frontier models require massive parallel compute, memory bandwidth and networking. This is where Nvidia’s position is strongest, because customers need flexibility, software maturity, system reliability and scale. In a market where falling behind can be strategically costly, Nvidia became the safest and most productive platform.
But training alone cannot carry the entire long-term thesis. The number of companies training the largest frontier models is limited, and training is more episodic than daily usage. The next phase depends much more on inference: the actual running of models after they have been trained.
Inference can become much larger because every chatbot answer, coding suggestion, search result, recommendation, image generation, agentic task or enterprise workflow creates compute demand. If AI becomes embedded in software development, customer service, advertising, healthcare, industrial automation and personal productivity, inference can become a continuous demand pool rather than a one-time training event.
This is where token elasticity matters. If the cost per token falls, usage may rise even faster. Cheaper inference can make more AI products economically viable, and more complex agents may consume far more tokens than simple chatbot queries. In that version of the future, efficiency does not reduce total compute demand; it expands the market by making new use cases possible.
The risk is that inference is also more contestable. Training frontier models rewards flexibility and system performance. Production inference often rewards cost efficiency. Once workloads become predictable and high-volume, hyperscalers have a stronger incentive to shift them toward custom ASICs such as Google TPUs, Amazon Trainium and Inferentia, Meta MTIA or Microsoft Maia. Nvidia can still win a large part of inference, especially where workloads are complex or customers want the standard platform, but it cannot be assumed that all future inference growth will carry the same margin profile as today’s high-end training demand.
Enterprise AI is the proof point
The long-term demand case ultimately depends on whether AI creates enough economic value for end customers. Hyperscalers can spend ahead of demand for a period, especially when compute is scarce and strategically important. But over time, cloud customers and enterprises need to generate revenue growth, cost savings, productivity gains or better products from AI. Otherwise, the infrastructure layer becomes harder to justify.
Enterprise AI adoption is clearly real, but still early. Coding assistants, copilots, customer service automation, document analysis and workflow agents are moving into the enterprise stack. Some areas, especially software engineering and customer support, already show visible productivity potential. But broad adoption is not the same as mature financial impact. Many companies are still testing use cases, integrating tools and learning where AI produces measurable returns.
That makes this part of the Nvidia thesis less proven than the hyperscaler capex data. If enterprise AI follows the cloud playbook, today’s infrastructure build-out may look rational in hindsight: capacity is built first, applications and workflows follow, and usage gradually expands across the economy. If the revenue layer does not develop fast enough, hyperscalers may eventually become more disciplined, even if AI remains strategically important.
This is the most important demand uncertainty. Nvidia does not need every enterprise to become AI-native tomorrow, but the direction must be clear. The longer enterprise monetization remains vague, the more the market will question whether AI infrastructure spending is running ahead of actual cash flow creation.
Structural trend, cyclical excess
The most balanced view is that Nvidia is exposed to a structural AI build-out, but the current pace of demand may still be cyclically extreme. AI infrastructure is not a temporary consumer fad. The move toward accelerated computing is real, and demand is supported by training, inference, enterprise adoption, cloud platforms and sovereign AI. At the same time, the current market is shaped by urgency, scarcity and competitive fear. Customers are building ahead of demand, securing capacity and racing to avoid falling behind.
That combination can produce extraordinary growth and margins in the early phase, but it can also create digestion periods later. If supply catches up, rental prices fall, utilization disappoints or hyperscalers demand clearer returns, Nvidia could remain a world-class company while the growth rate and margin profile normalize.
So the demand case is strong, but not risk-free. For Nvidia, the next phase will be less about whether AI matters and more about whether AI infrastructure turns into durable customer cash flows. If hyperscalers can prove AI ROI, if enterprise adoption deepens, and if inference scales while staying close to Nvidia’s platform, the runway remains enormous. If not, Nvidia may still be the largest winner of the first AI infrastructure wave, but investors may need to value it more like a cyclical capex beneficiary than a permanently expanding toll road.

Chapter 4: Competition
Competition does not need to destroy Nvidia
The competition debate around Nvidia is often too binary. Either Nvidia is treated as untouchable, or every new AI chip is presented as the beginning of the end. Both framings miss the more realistic risk. Nvidia does not need to lose its leadership position for competition to matter. It only needs customers to gain enough alternatives to reduce pricing power, shift selected workloads away from Nvidia, or make the market value future margins more conservatively.
Nvidia is not being attacked by one single rival. AMD wants to become the credible merchant GPU alternative. Hyperscalers want to move more internal workloads to custom silicon. Broadcom and Marvell help those hyperscalers design custom chips. Chinese players are trying to fill the gap created by U.S. export restrictions. None of these threats needs to replace Nvidia everywhere. The more important question is which parts of the future profit pool become more contested.
AMD is the second-source candidate
AMD is the most direct competitor because it sells merchant AI accelerators to external customers. Its Instinct products and ROCm software stack give hyperscalers and enterprises a real alternative to Nvidia, especially where customers have enough engineering capacity to optimize workloads themselves.
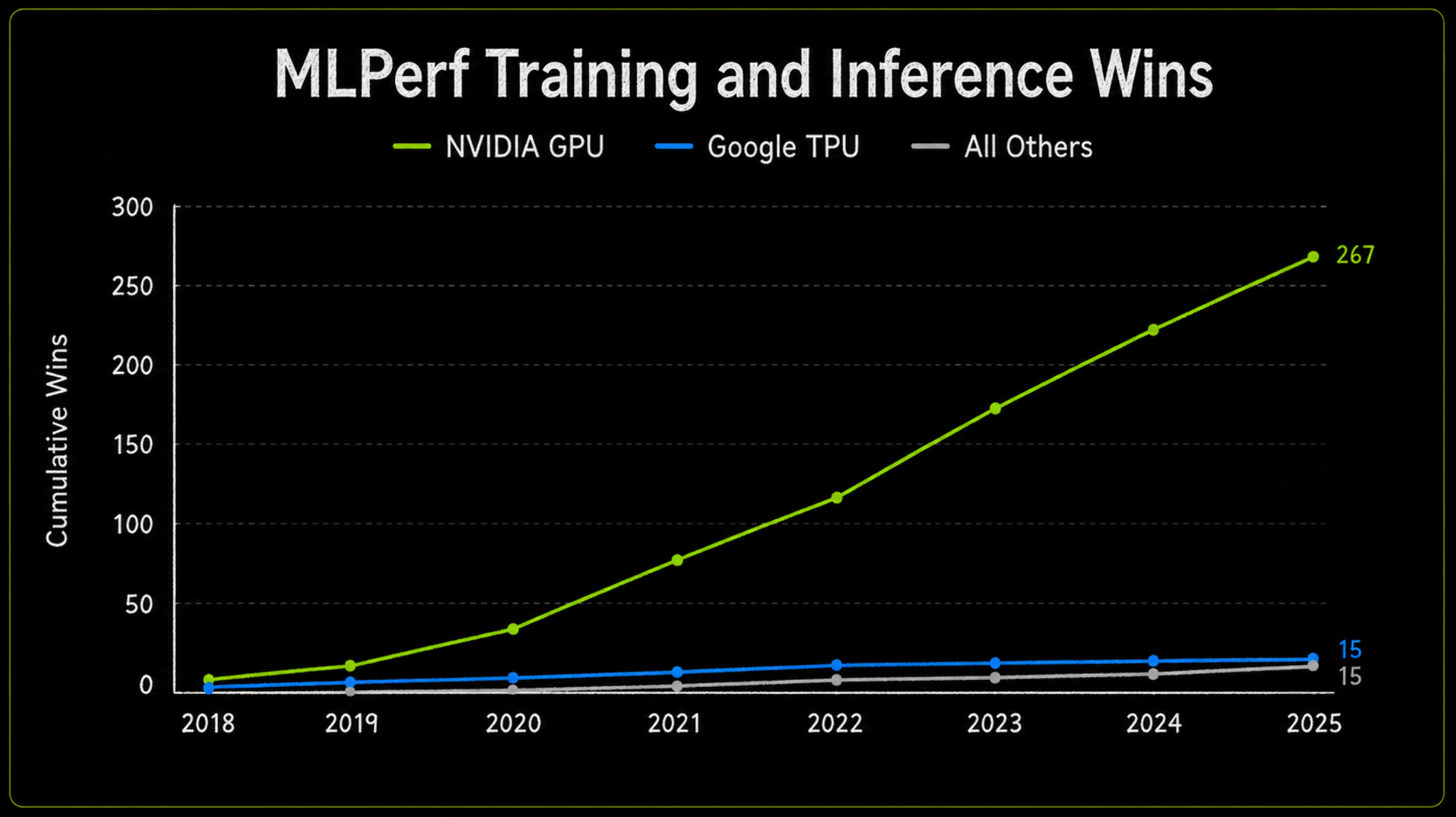
AMD’s strongest argument is not that it has already matched Nvidia’s full platform. It is that large customers badly want a second source. Hyperscalers dislike dependency. They want supply diversity, better pricing, negotiating leverage and a fallback if Nvidia supply remains constrained. For a company spending tens of billions on AI infrastructure, even a partially competitive alternative can be valuable.
That does not mean AMD has solved the full problem. Nvidia’s lead is not just chip performance. It is software maturity, developer familiarity, libraries, networking, system integration and customer trust. AMD can close benchmark gaps faster than it can close ecosystem gaps. A chip can improve in one generation; an installed developer base takes much longer to build.
So AMD is relevant, but the likely impact is gradual. It is less likely to cause an immediate collapse in Nvidia revenue and more likely to create pressure at the margin. If AMD becomes good enough for more production workloads, Nvidia remains the preferred platform but loses some freedom to price as if customers have no alternative.
Custom ASICs are the deeper threat
The more structural competitive risk comes from custom ASICs. A GPU is flexible and remains especially valuable when models, software and architectures are changing quickly. A custom ASIC is narrower, but can be cheaper and more efficient when the workload is stable, repetitive and high volume.
That distinction is crucial for AI. Frontier training still favors flexibility, scale and software maturity. Nvidia is strongest there. Production inference can be different. Once a model is deployed and the workload becomes predictable, cost per query starts to matter much more. That is why Google has TPUs, Amazon has Trainium and Inferentia, Meta has MTIA and Microsoft has Maia. These chips are not designed to make Nvidia irrelevant across all of AI. They are designed to reduce dependence on Nvidia where the economics are easiest to optimize.
For hyperscalers, the incentive is obvious. Nvidia’s margin is their cost. If a cloud platform can run a predictable internal workload on its own silicon at lower cost, it can protect margins, reduce capex pressure and gain strategic control. This becomes especially important if inference grows into the largest part of AI usage. Nvidia can remain dominant in frontier systems while still losing some of the most repetitive, cost-sensitive workloads to internal silicon.
That is why ASICs are a more serious long-term margin risk than AMD. AMD competes inside the merchant accelerator market. Custom silicon can reduce the size of the merchant opportunity in selected workloads.
Complementary or substitutionary?
The difficult part is that custom ASICs can be both complementary and substitutionary. They are complementary when they expand total AI infrastructure demand, handle workloads Nvidia could not supply anyway, or sit inside broader systems where Nvidia still controls the networking and system architecture. They become substitutionary when they take workloads that would otherwise have run on Nvidia systems at high margins, especially in high-volume inference.
The honest answer is that we do not yet have enough clean displacement data. We know hyperscalers are investing heavily in custom silicon. We know they have strong economic incentives to use it. We know inference is more suitable for ASICs than frontier training. But we do not yet know how much Nvidia demand is truly being replaced rather than supplemented.
That uncertainty should be visible in the valuation. A bull case can assume ASICs remain mostly complementary. A more cautious base case should assume they gradually reduce Nvidia’s pricing power in predictable inference.
The system response
Broadcom and Marvell matter because they help hyperscalers build this escape route. They are not trying to beat Nvidia by selling one general-purpose AI GPU to the entire market. Their role is different: they enable custom silicon for the largest cloud platforms. If cloud companies want more internal silicon, Broadcom and Marvell can capture value that might otherwise have gone toward Nvidia’s addressable market.
Nvidia’s response is to keep the battlefield at the system level. Through technologies such as NVLink Fusion, Nvidia is trying to keep custom silicon close to its own architecture. Nvidia does not necessarily need to supply every chip if it can remain the platform that connects, coordinates and optimizes the system. If custom silicon becomes part of Nvidia-connected AI factories, the threat is more manageable. If it becomes independent of Nvidia’s stack, the threat becomes more serious.
China adds a separate regional risk. U.S. export restrictions limit Nvidia’s ability to sell its most advanced AI chips into China, which gives domestic Chinese alternatives more room to develop. That does not break the Western hyperscaler thesis, but it does reduce the global addressable market and adds geopolitical uncertainty.
The real fault line
The most useful way to think about Nvidia’s competitive position is by workload.
Nvidia is strongest where workloads are complex, fast-changing and system-dependent. Frontier training, large-scale model development, multi-modal systems, enterprise deployments and mixed workloads all favor flexibility, mature software and reliable system performance. These are the areas where Nvidia’s full stack matters most.
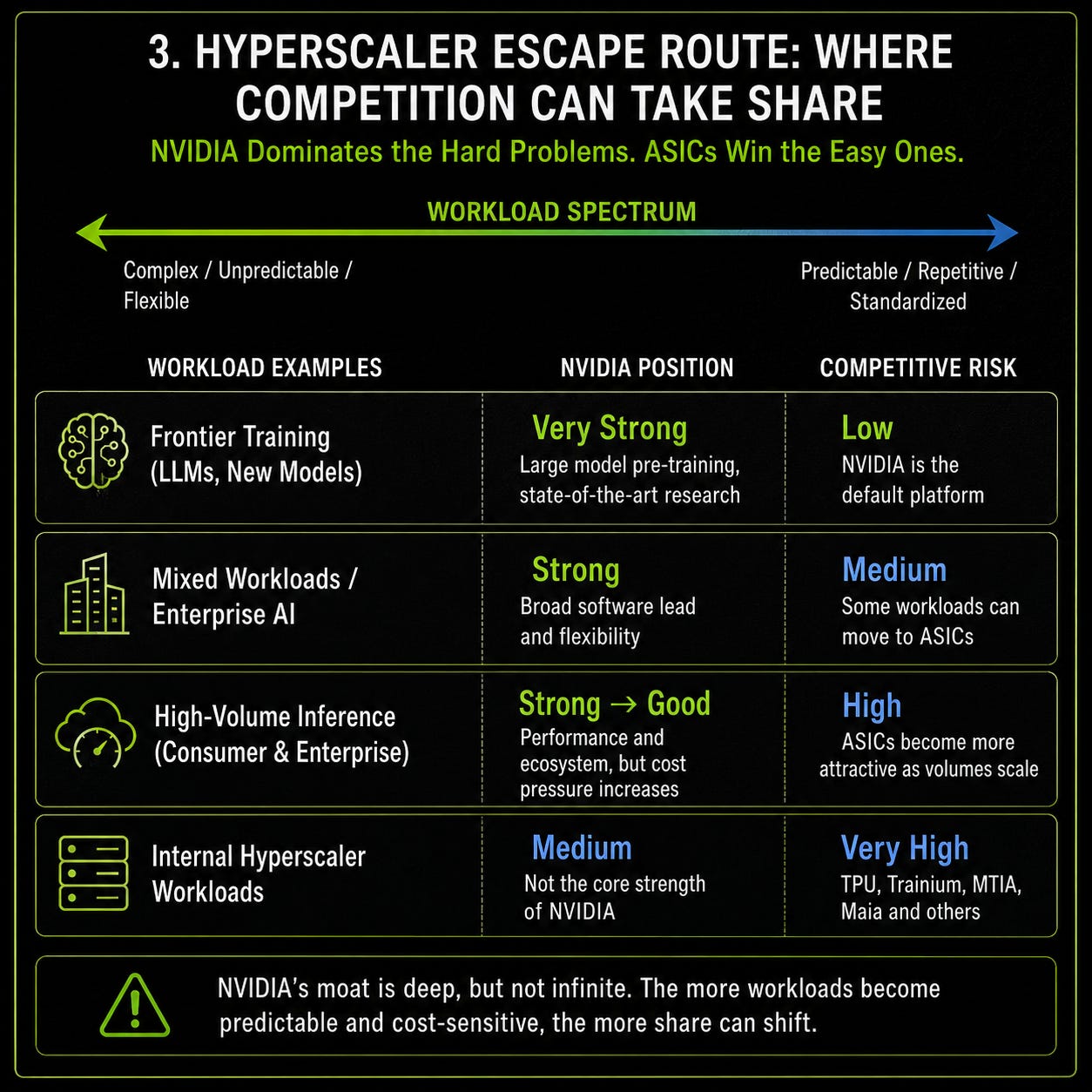
Competition is more dangerous where workloads are predictable, repetitive and cost-sensitive. Production inference is the obvious example. Once a workload is stable, the customer has a strong reason to optimize cost. That is where AMD, ASICs and internal hyperscaler chips gain relevance.
This distinction matters because Nvidia does not need to win every future AI workload to remain an exceptional company. But it does need to retain enough of the high-value workload layer to defend its margins. If AI becomes more agentic, multi-step and system-heavy, Nvidia’s position strengthens. If much of AI usage becomes standardized inference optimized for cost, the margin story becomes more vulnerable.
The competitive risk will probably not appear as one dramatic event. It will show up gradually in pricing, margins, customer behavior and workload mix. If gross margins fall while demand remains strong, customers may be gaining leverage. If hyperscalers begin offering more external AI capacity on their own chips, ASICs are moving beyond internal workloads. If AMD becomes a default second source, Nvidia’s margin umbrella narrows.
The key point is simple: competition is unlikely to destroy Nvidia’s growth story in the near term, but it can change the quality of that growth. Nvidia can remain the leader and still face lower future returns if the profit pool becomes more contested than the market currently assumes. The risk is not that Nvidia stops winning. The risk is that winning becomes less profitable.
Chapter 5: The Physical Limits Behind AI
Nvidia is asset-light, but AI is not
Nvidia is often described as an asset-light company, and financially that is true. It does not own the advanced fabs that manufacture its chips, it does not carry the same capital burden as TSMC, Samsung or Intel, and it can generate enormous revenue from a relatively limited internal capital base. That is one of the reasons Nvidia’s returns on capital look so exceptional.
But the AI infrastructure cycle underneath Nvidia is not asset-light. Behind every Nvidia system sits a physical chain of fabs, packaging capacity, high-bandwidth memory, substrates, power, cooling, datacenter space, grid connections, logistics and financing. Nvidia can design the chips, software and systems, but it still depends on whether the rest of that chain can scale with demand.

That is why supply chain risk is not a side note. Nvidia may sit close to the compute layer of AI, but it does not fully control the physical system that makes that compute possible.
TSMC, CoWoS and HBM
The most obvious dependency is TSMC. Nvidia relies heavily on TSMC for the advanced manufacturing behind its highest-end AI chips. This relationship is a major strength because TSMC remains the most capable foundry for leading-edge semiconductors. It allows Nvidia to focus on architecture, systems and software without carrying the capital burden of owning fabs.
But it is also a vulnerability. There are few true substitutes at the high end. If TSMC capacity is constrained, if yields disappoint, or if geopolitical tension around Taiwan escalates, Nvidia cannot simply move production elsewhere overnight. Strong demand only matters if products can actually be manufactured, packaged and shipped.
The next bottleneck is advanced packaging. AI accelerators are not limited only by wafer supply. CoWoS and similar technologies are critical because they allow large compute dies and high-bandwidth memory to work together efficiently. If packaging capacity is the constraint, Nvidia’s growth can be capped even when customer demand remains strong.
HBM is the third layer. Modern AI workloads are memory-intensive, not only compute-intensive. Training and inference require fast access to large amounts of data, which makes SK hynix, Samsung and Micron strategically important. If HBM supply is tight, if new memory generations ramp slowly, or if memory costs rise, Nvidia’s ability to deliver systems at scale becomes more difficult.
These constraints cut both ways. Scarcity has helped Nvidia maintain pricing power because customers that need capacity have limited alternatives. But scarcity also places a physical ceiling on growth. If supply expands quickly, Nvidia may ship more systems, but customers may also gain more negotiating power.
The hidden inputs behind memory
HBM also shows how deep the physical chain behind Nvidia really goes. Nvidia does not produce memory itself, but its AI systems depend heavily on memory suppliers. Those suppliers depend on specialized inputs used in semiconductor manufacturing, including helium for processes such as plasma etching, deposition and wafer cooling.
That creates a second-order geopolitical risk. Qatar accounts for a meaningful share of global helium supply, and disruption around the Gulf or Hormuz can therefore matter for the semiconductor chain. This does not mean Nvidia is directly exposed to an oil chokepoint, but it does show how stress can move through unexpected layers: helium supply, Korean memory production, HBM availability and eventually AI system ramps.
The risk should not be overstated. Samsung and SK hynix have secured additional long-term U.S.-sourced helium supply through suppliers such as Linde and Air Products, and South Korea has indicated that it has several months of helium supply and multiple procurement channels. That makes an immediate memory shutdown unlikely. Still, the example is useful because it shows that Nvidia’s growth depends on more than chip design. It depends on materials, energy, logistics and geopolitical stability.
Energy, datacenters and financing
The physical constraints behind AI do not stop at chips. Nvidia’s customers also need power, cooling, land, grid connections and financing. A GPU shipment only creates value if it can be installed into a datacenter with enough electricity, cooling and utilization to generate attractive returns.
This is where broader macro shocks matter. A closure of Hormuz, for example, would not primarily affect Nvidia through direct oil exposure. It would matter through energy prices, inflation expectations, interest rates, logistics and the cost of running or financing datacenters. Higher energy costs can make AI infrastructure more expensive to operate. Higher inflation can keep rates elevated. Higher rates make long-duration infrastructure investments harder to justify.
The strongest hyperscalers can absorb more pressure than smaller buyers. Microsoft, Amazon, Google and Meta have the balance sheets to keep investing through stress. But the marginal buyers are more vulnerable. Neoclouds, AI infrastructure startups, smaller datacenter developers and leveraged infrastructure vehicles depend more heavily on external financing. If private credit tightens or liquidity dries up, those buyers may delay projects, reduce orders or become more selective.
That does not mean a macro shock would end the AI build-out. The structural direction can remain intact while the pace changes. Nvidia’s demand does not need to disappear for growth expectations to reset. A slower deployment pace, tougher financing environment or higher power cost can shift the market from “secure capacity at any price” toward “optimize returns on existing capacity.”
Taiwan, China and the physical limit
The largest geopolitical supply-chain risk remains Taiwan. TSMC is central to the advanced semiconductor world, and Nvidia’s reliance on TSMC creates exposure to Taiwan’s geopolitical position. This is difficult to model because it is a low-frequency but high-impact risk. A major disruption would not be a normal cyclical downturn. It would affect the entire global semiconductor ecosystem.
China adds a different problem. U.S. export restrictions limit Nvidia’s ability to sell its most advanced AI products into China. That directly reduces part of the addressable market and indirectly supports domestic Chinese alternatives. The H20 issue also showed how quickly regulation can affect economics: products designed around one set of export rules can become impaired when rules change.
The supply-chain conclusion is therefore balanced. Nvidia’s physical constraints have helped create its current economics. Scarce capacity, priority access and system complexity all strengthen the company’s position. But the same physical world also creates risks that a pure software company would not face. Nvidia can design the road, but the road still requires fabs, packaging, memory, helium, energy, datacenters and financing.
That is why the AI infrastructure cycle should not be valued as if it can scale without friction. The opportunity is enormous, but it is still bound by the physical and geopolitical limits of the system underneath it.
Normally, this is where the paid section begins.
For this company deep dive, we are keeping the full analysis free.
Below is the part we would normally reserve for paid readers: the financial foundation, cash flow map, owner yield, valuation, rating, risks, and the conditions that would invalidate our thesis.
If you find this valuable, you can support TVF enormously with a like, comment, share or restack.
Chapter 6: Financial Assumptions
The base case
Our base case does not assume that the AI cycle breaks. Nvidia remains the leading infrastructure platform for accelerated compute, hyperscalers continue to invest, inference keeps scaling and enterprise AI adoption gradually deepens.
But the model also does not assume that today’s perfect environment continues in a straight line.
The first phase of the AI infrastructure cycle has been unusually favorable for Nvidia. Demand exceeded supply, hyperscalers were racing to secure capacity, credible alternatives were limited at scale, and Nvidia’s full-stack position allowed the company to capture exceptional margins. That combination created one of the strongest financial profiles in the market.
Our base case assumes Nvidia remains exceptional, but that the cycle becomes more disciplined. Customers become more selective, supply improves, custom silicon becomes more relevant, and the return on AI infrastructure starts to matter more than simply securing capacity at any price.
Revenue: strong, but not smooth
The model assumes revenue growth of 80% in 2026, followed by 40% in 2027 and 15% in 2028. That reflects the near-term strength of the Blackwell/Rubin ramp, continued hyperscaler demand and Nvidia’s position as the default platform for large AI workloads.
The more important assumption comes after that.
In 2029, we model 0% revenue growth. That is the digestion year. This does not mean AI demand disappears, and it does not mean Nvidia loses its position. It means the market moves from emergency build-out to capacity discipline. Hyperscalers still need AI infrastructure, but they also need to prove utilization, cloud returns and enterprise monetization. At the same time, Google, Meta, Amazon and Microsoft have strong incentives to solve part of their capacity needs internally through custom silicon.
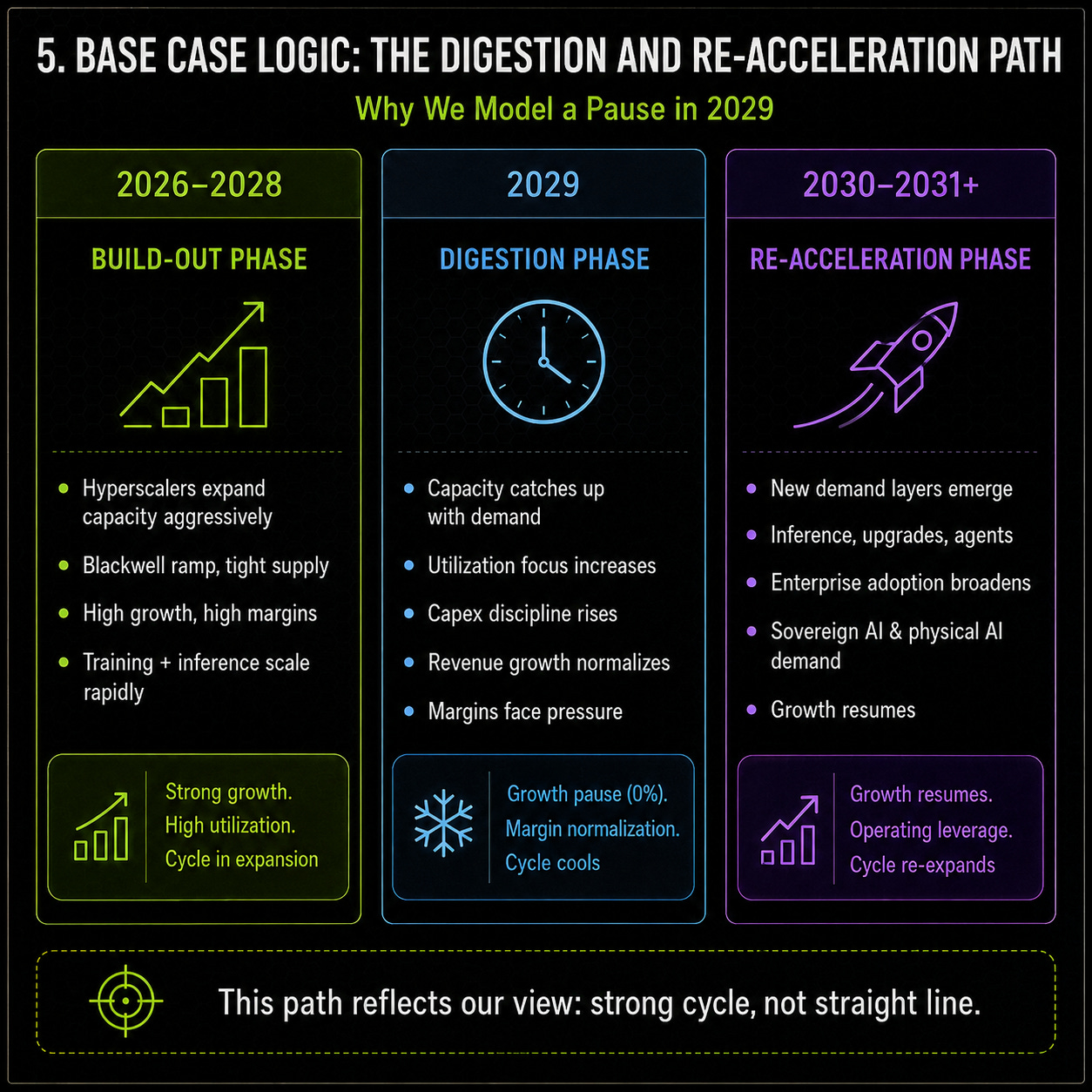
The digestion year also includes a macro stress layer. In this scenario, we assume that geopolitical pressure around Hormuz feeds through into higher energy prices, stickier inflation and a more cautious investment environment. That does not directly break Nvidia’s demand, but it does make AI infrastructure more expensive to finance and operate. Datacenters need power, cooling, grid capacity and long-duration capital. If energy costs rise and rates remain elevated, even large hyperscalers become more disciplined, while neoclouds and leveraged datacenter projects become more vulnerable. That is why 2029 is not modeled as a collapse, but as a pause: AI remains structural, yet the pace of new capacity additions slows as customers focus more on utilization, returns and cost per unit of AI output.
After that digestion year, the model assumes growth returns to 10% in 2030 and 15% in 2031. This reflects the idea that AI infrastructure remains a structural growth market, but not one that expands without cycles. Nvidia can still grow after a pause because inference demand, upgrade cycles, networking content, sovereign AI and broader enterprise adoption can create new demand layers.
That makes the base case more realistic than a smooth growth line. It assumes Nvidia does not crash, but also does not escape the cyclicality of its customers’ capex decisions.
Margins: normalization, not collapse
The margin path follows the same logic. EBITDA margin declines from 67% in 2026 to 59% in 2031. EBIT margin moves from 65.5% to 58%, while net margin declines from 55% to 48%.
This is still an extremely strong margin profile. Even at the end of the forecast period, Nvidia remains one of the most profitable large companies in the world. The model does not treat Nvidia like a commodity semiconductor company.
That is because Nvidia’s economics are protected by more than chip performance. CUDA, software libraries, networking, rack-scale systems, customer trust and deployment speed all help Nvidia capture more value than a normal component supplier. Customers are not only buying GPUs. They are buying a platform that reduces execution risk and allows expensive AI infrastructure to work at scale.
But we do assume pressure.
Some of today’s profitability is supported by scarcity. When customers are capacity-constrained and alternatives are limited, Nvidia has unusual pricing power. Over time, TSMC packaging capacity, HBM supply and broader AI infrastructure availability should improve. That does not remove Nvidia’s moat, but it can reduce the scarcity premium.
Competition adds another layer. AMD does not need to replace Nvidia to pressure margins. It only needs to become a credible second source. Custom ASICs are more important because hyperscalers can move predictable, high-volume inference workloads onto internal silicon. That does not destroy Nvidia’s role in frontier systems, but it can make part of the future profit pool more contested.
Energy costs, financing costs and macro pressure also matter. Higher rates or higher energy prices do not directly break Nvidia’s model, but they make AI infrastructure more expensive for customers. That pushes the market from “secure capacity at any price” toward “optimize return on capacity.”
So the model assumes margin normalization, not margin destruction.
Free cash flow: the real output
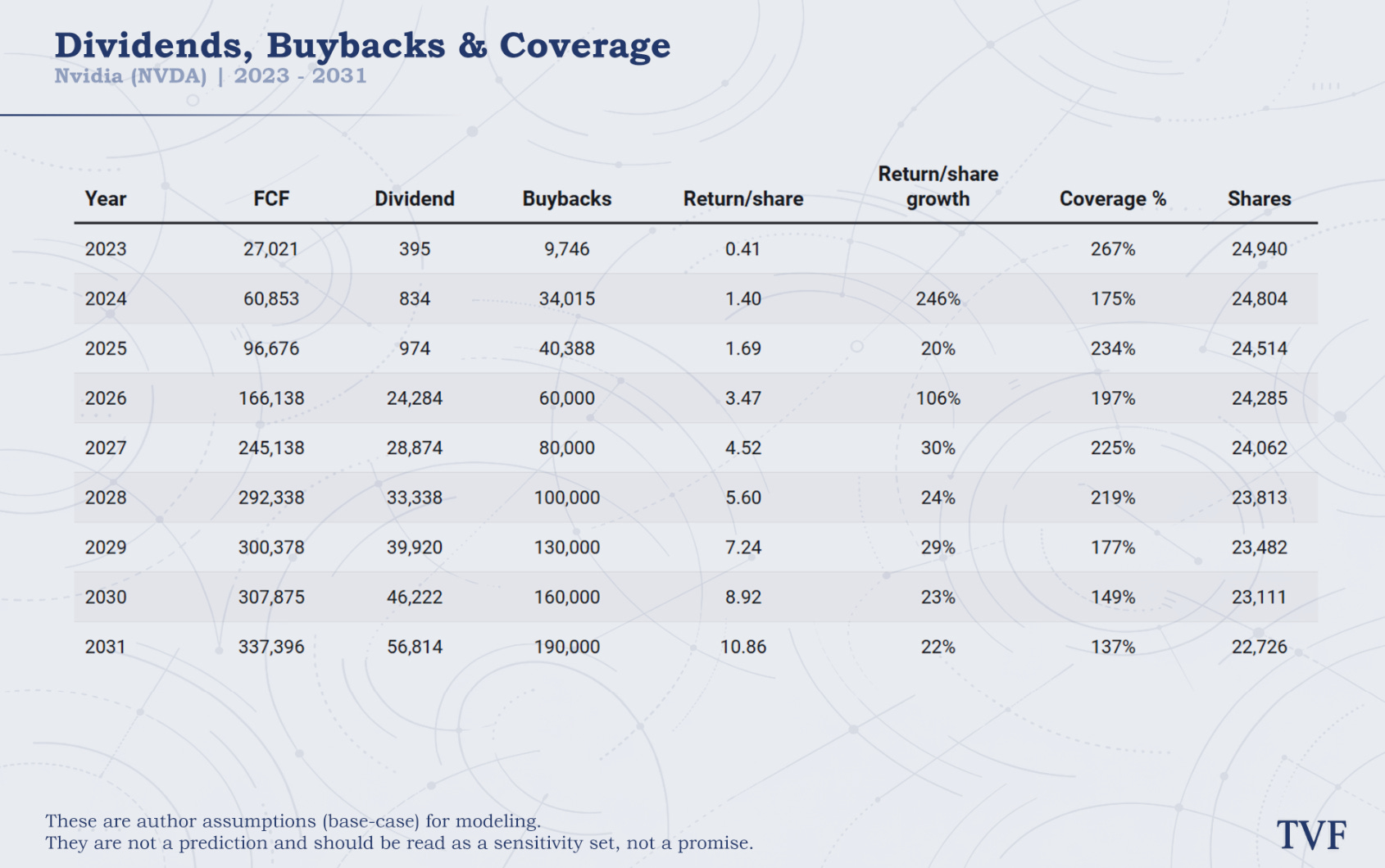
The digestion year is visible in 2029. Revenue does not grow, margins continue to normalize, but FCF still rises to roughly $300.4 billion because the company remains extraordinarily profitable and working capital becomes less of a drag. After that, FCF reaches about $307.9 billion in 2030 and $337.4 billion in 2031.
That is the central point. Even with a flat revenue year and lower margins, Nvidia still generates enormous cash flow in this base case. The company is fabless, highly profitable and capital-light relative to the scale of revenue it can produce. Capex increases in absolute terms, but remains modest as a percentage of revenue.
The financial risk is therefore not balance sheet risk. Nvidia has minimal leverage relative to EBITDA and a strong liquidity position. The real risk is whether revenue growth and margins remain high enough to justify the valuation.
Capital returns
The model also assumes significant capital returns.
Buybacks rise from $60 billion in 2026 to $190 billion in 2031, while dividends increase over time as well. This is not the core Nvidia thesis. Nvidia is not a dividend story. The more important point is that the company could generate enough free cash flow to fund R&D, maintain strategic flexibility, support supply commitments and still return large amounts of capital to shareholders.
Buybacks should not be treated as value creation by themselves. They mainly support the per-share outcome by reducing share count. The real value still comes from the operating engine: revenue, margins and free cash flow conversion.
What the assumptions say
This base case is strong, but no longer euphoric.
It assumes Nvidia remains the dominant AI infrastructure platform, but also assumes the first phase of scarcity and emergency hyperscaler spending normalizes. Revenue grows sharply at first, pauses in FY2029, and then resumes growth. Margins remain exceptional, but drift lower. Free cash flow expands massively, but the model does not assume today’s peak conditions last forever.
That is the right bridge into valuation. Nvidia can remain one of the best businesses in the world and still be difficult to buy if the market already prices in too much of the future cash flow.
Chapter 7: Valuation
Valuation summary
Today: $211.14
DCF fair value: $273.76
Based on a 9.5% WACC and 2.5% terminal growth
Monte Carlo median fair value: $253.49
Based on 1,000 scenario-weighted simulations
2031 P/FCF target: $445.39
Based on a 30x P/FCF multiple
Current upside to DCF fair value: 29.7%
Monte Carlo upside cases: 64.3%
Monte Carlo likely value range: $175 – $329
TVF target 2031: $359.58
Expected annual return: 10.2% per year
What the valuation says

Nvidia still offers upside in our base case, but the margin of safety is not extreme. The DCF fair value of $273.76 implies roughly 29.7% upside from today’s price, which looks attractive on the surface. But Nvidia is not a simple company to value with one clean DCF output. The business is exceptional, yet the range of possible outcomes is unus4ually wide because Nvidia is still partly tied to the pace of AI infrastructure construction.
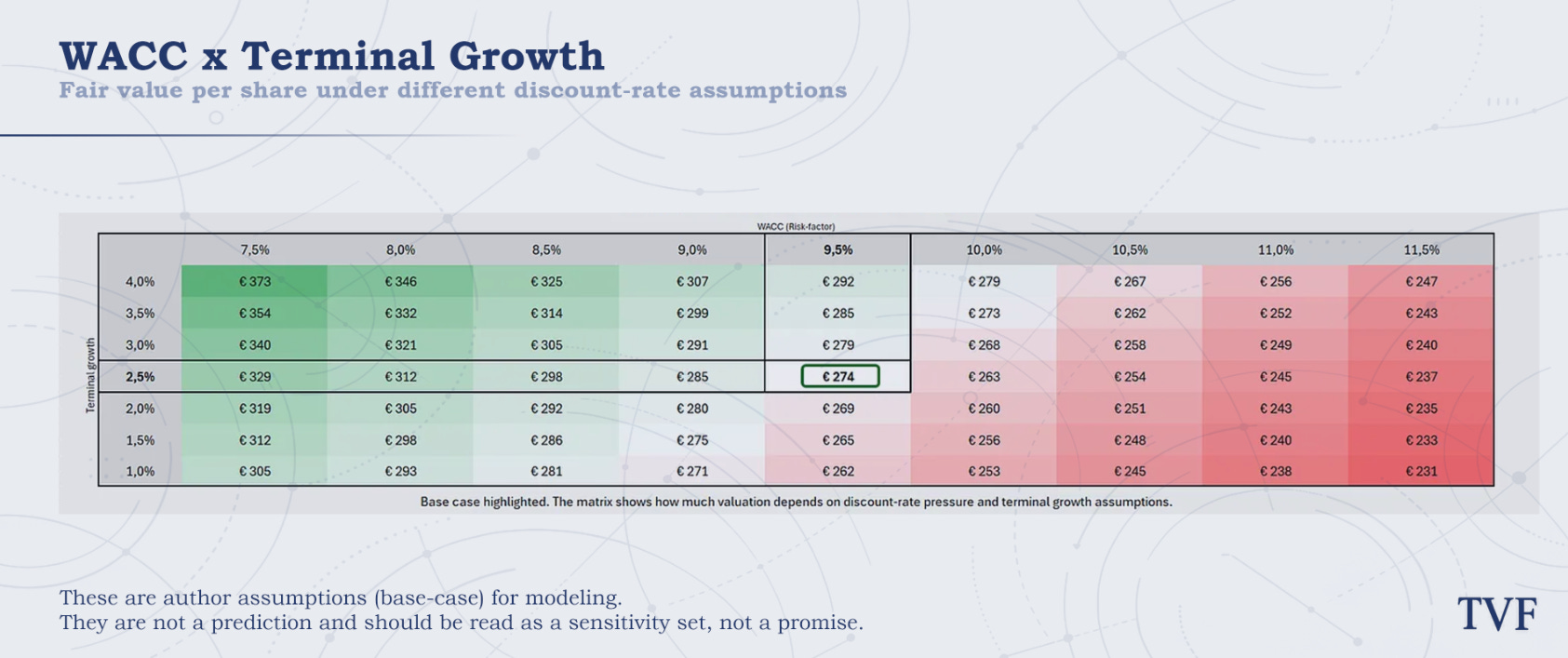
The DCF fair value is most sensitive to the discount rate and terminal growth assumptions. In our base case, we use a 9.5% WACC and 2.5% terminal growth.
The sensitivity map shows that Nvidia’s valuation remains attractive under several reasonable assumptions, but it is not immune to higher discount rates. If the WACC (Cost of Capital) rises toward 11.0–11.5%, fair value compresses quickly, even if the company continues to grow. On the other hand, if Nvidia deserves a lower risk premium and can sustain stronger terminal growth, the valuation moves meaningfully above $300.
This is important because Nvidia is still a long-duration AI infrastructure equity. The business already generates enormous cash flow, but the stock price still depends heavily on how durable investors believe the AI growth cycle will be after the explicit forecast period.
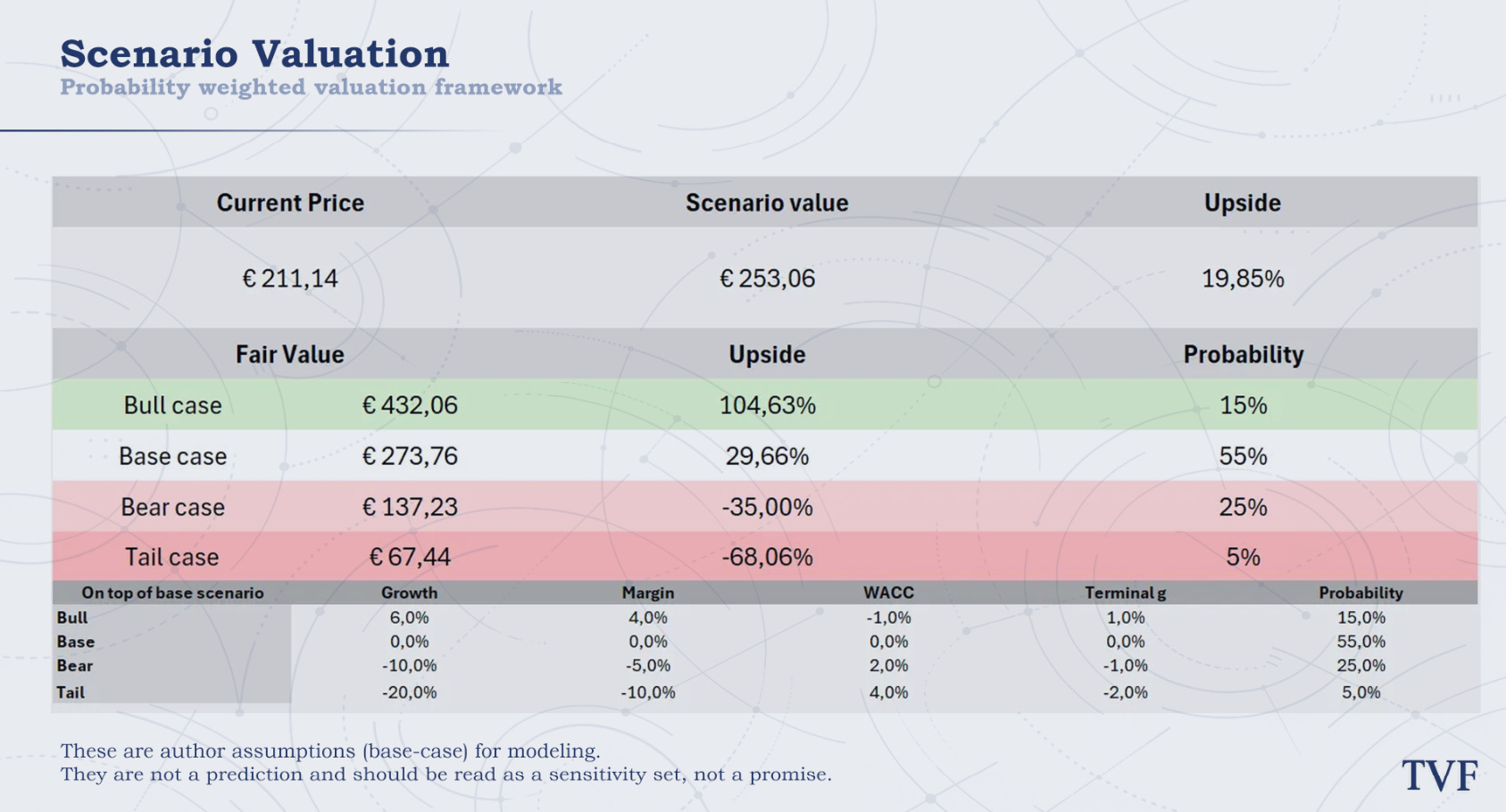
That is why we also use a scenario-weighted valuation. In the bull case, Nvidia is worth $432.06 per share, as the AI build-out remains stronger for longer and the company continues to capture exceptional margins. In the base case, fair value is $273.76, with strong growth but gradual margin normalization. In the bear case, fair value falls to $137.23, reflecting a more meaningful capex digestion cycle. In the tail case, fair value drops to $67.44, where AI overbuild, weaker ROI, higher financing costs and margin pressure combine.
The probability-weighted scenario value is $253.06, implying about 19.9% upside. This is lower than the standalone DCF because it explicitly gives weight to bear and tail outcomes. That matters for Nvidia. The company may be one of the best businesses in the world, but the stock is still vulnerable if investors start treating the current AI infrastructure cycle as closer to peak build-out than durable compounding.
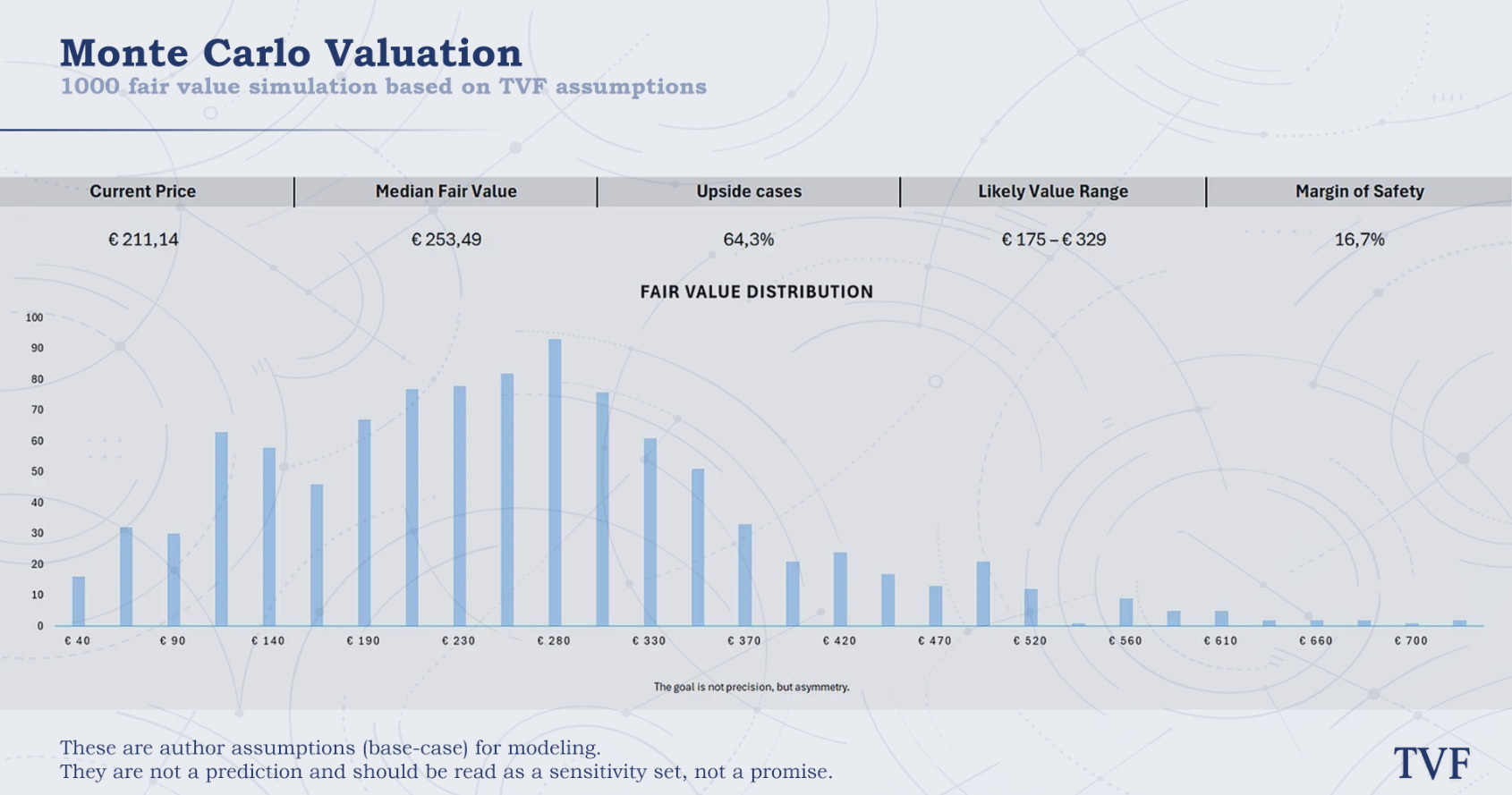
The Monte Carlo valuation gives a similar result. Across 1,000 scenario-weighted simulations, the median fair value is $253.49, with 64.3% of outcomes above the current price. The likely value range is $175 - $329, which shows both the upside and the uncertainty. Nvidia is not obviously overvalued, but it is also not priced with a huge margin of safety.
Looking toward 2031, our TVF target is $359.58 per share, implying an expected annual return of roughly 10.2%.
Our conclusion is therefore balanced: Nvidia remains investable at today’s price, but only if investors accept the cyclicality behind the AI infrastructure build-out. The upside is still real, but the valuation no longer allows for lazy assumptions. Nvidia does not need perfection to work from here, but it does need the AI cycle to avoid a deeper capex reset.
Chapter 8: Rating

Quality — 9.5/10
Nvidia is one of the highest-quality companies in the public market. The company combines exceptional margins, enormous free cash flow generation, very high returns on capital and a balance sheet with minimal financial risk. The business is also structurally capital-light relative to its revenue base, because Nvidia does not own the fabs that manufacture its chips.
The score is not a perfect 10 because today’s financial profile is partly amplified by an extreme AI infrastructure cycle. Margins above 60% at the operating level are world-class, but they are also supported by scarcity, customer urgency and limited alternatives at scale.
MOAT — 9.5/10
Nvidia has one of the strongest moats in technology. The moat is not just GPU performance, but the combination of CUDA, software libraries, developer mindshare, networking, rack-scale systems and customer trust. That full-stack position makes Nvidia the default platform for the most complex AI workloads.
The moat is not unlimited. AMD can become a more credible second source, and hyperscalers have strong incentives to move predictable inference workloads to internal ASICs. This does not destroy Nvidia’s position, but it can limit pricing power over time.
Growth — 8.5/10
Nvidia’s growth outlook remains exceptional. Near-term demand is supported by Blackwell and Rubin ramps, hyperscaler spending, inference scaling, sovereign AI and the broader build-out of AI factories.
Still, this is not a straight-line growth story. The first AI infrastructure wave has been driven by scarcity and emergency capacity build-out. Over time, customers will focus more on utilization, returns and cost per unit of AI output. Inference, upgrades, enterprise AI and eventually physical AI can create new demand layers, but Nvidia remains cyclically exposed to the pace of infrastructure construction.
Risks — 6.0/10
The risk score is where Nvidia is most clearly penalized. The company is exposed to hyperscaler capex cycles, customer concentration, TSMC/Taiwan risk, export restrictions, energy constraints, datacenter bottlenecks and competition from custom ASICs.
The main risk is not that AI disappears. The more realistic risk is that the pace of new AI infrastructure construction slows after the first extreme build-out phase. Nvidia is partly the builder of the AI road, not a pure toll collector on every AI transaction. Its balance sheet, product leadership and software ecosystem reduce the risk, but they do not remove it.
Valuation — 7.0/10
The valuation is positive, but not cheap enough to justify a higher score. Our base case DCF fair value is $273.76 per share, compared with a current price of $211.14. The probability-weighted scenario value is $253.06, while the Monte Carlo median fair value is approximately $253.49.
That supports the view that Nvidia is still investable, but not deeply mispriced. The Monte Carlo analysis shows that about 64% of simulated outcomes are above the current price, with a likely value range of roughly $175–$329. Upside exists, but investors are already paying for a large part of the quality upfront.
Conclusion
Nvidia is one of the rare companies where the quality of the business is not the difficult part of the analysis.
The company has built one of the strongest positions in modern technology: accelerated compute, CUDA, networking, full-stack systems and a developer ecosystem that is extremely difficult to replicate. Nvidia does not merely sell chips into the AI cycle. It supplies a large part of the physical infrastructure that allows AI to scale.
That makes Nvidia exceptional, but not simple.
The central question is whether Nvidia can remain the premium infrastructure layer of AI as the market moves from the first explosive build-out toward broader inference, enterprise adoption, sovereign AI and eventually physical AI. If that transition happens smoothly, Nvidia can keep compounding. If the cycle enters a deeper digestion phase, growth and margins can normalize faster than investors expect.
That is the main distinction. Nvidia is not a pure toll road like a payment network or a pipeline. It is still partly the builder of the AI road. Builders can earn extraordinary profits when construction is running at full speed, but they also feel it when customers slow new capacity additions.
All things considered, Nvidia deserves an A-rating in our framework. The company scores extremely high on quality and moat, strongly on growth, but lower on risk and valuation. That prevents a higher rating. A company can be world-class and still not deserve an A+ rating if the scenario risk leaves limited room for disappointment.
For now, Nvidia remains investable, but only with discipline. The thesis works if Nvidia keeps control over the AI system layer and the next phases of AI demand absorb the current infrastructure build-out. This is still one of the best businesses in the world, but it should be monitored as a scenario-dependent AI infrastructure thesis, not as a risk-free compounder.
If macro-economics is your thing, check out our other newsletters and subscribe. We recommend:



Author: Jeffrey Kieboom

Disclaimer & disclosures: This analysis reflects the author’s opinion at the time of writing and is not investment advice. Investing involves risks, including the possible loss of (part of) the invested capital. All valuation outputs (including DCF, price targets, and expected returns) are model-based estimates and highly sensitive to assumptions (such as cash flows, leverage, capex, discount rate, and terminal growth). Facts may be sourced from public materials considered reliable, but their accuracy cannot be guaranteed.
Position / conflict of interest: The author holds no position in Nvidia. This can change at any time and without prior notice.
Note: I wrote this piece and conducted the research myself. AI was used for feedback/editing support and to generate some of the images.